[GIS原理] 10
![[GIS原理] 10](http://oss.aqwf.com/file/p/2024/03-07/1709753358379_0.png)
在知识传播途中,向涉及到的相关著作权人谨致谢意!
南师国家精品课程《地理信息系统》——主讲人:韦玉春老师
文章目录
【描述性统计】有一个群体,用均值、方差、标准差、众数,这叫描述性统计
【推断性统计】有一个大的区域,在这区域里采了几个样,对这几个样本用描述性统计。然后用这个数据推断这个区域的数据。推断性统计基于概率论
【怎么往外推断呢?】数学分布(正态、二项分布),这个数服从什么分布,在某个概率下,这个分布是成立的–>进行向外推断
1 空间统计描述 1.1 描述性统计
【描述性统计】
对空间对象分布状况的统计对具有空间坐标的属性的统计
【举例】有多少
长三角地区城市分布具有聚集性?江苏省人均GDP是多少?
【基本统计量】
【正态分布】统计学中所有的东西,在大量的情况下,假设的都是正态分布
【规则!】如果你的数据不是正态分布,那么你的数据描述就要用另外一套指标
【举例】平均成绩是80分,你默认的假设是全班成绩是服从正态分布的–>如果全部成绩放在一起的分布不是正态的,那么这个平均成绩就是有偏差的,不合适的
1.2 探索性数据分析
【探索性数据分析】首先是寻找数据的模式和特点,再根据数据特点选择合适的模型。揭示数据中存在的模式
是空间推断性统计,探究“怎么分布的?”的问题
【解释】拿到数据后,要想清楚,你要做什么,你要怎么做,为什么而做?探索性数据分析:天天看数据,找数据的规律,找想法,找个研究方向
【探索性数据分析的重要性】认为,“在认识到你看来多好的测量了它以前,重要的是理解你能做什么”
【动手前的三个问题】
科学问题是怎么产生的:你拿到数据后要干嘛呢?解决的是什么问题?问题不一样,统计方法不一样。如何引导产生新的调查设计方案:你这个调查方案是怎么产生的,调查方案怎么选择如何继续进行分析:做完之后,将来怎么做呢?
【步骤】数据->数据的数学分布->概率论->推断
1.2.1 直方图
【直方图】
对样本数据按一定的分级方案(等间隔分级、标准差等)进行分级,统计记录落入各个级别中的个数或占总样本数的百分比,然后用条带图或柱状图表现出来。直方图可以直观反映采样数据分布特征、总体规律,可以用来检验数据分布和寻找数据离群值
【特点】
适用于空间对象为点和面的属性数据简单易用缺乏空间信息 1.2.2 Q-Q图
【Q-Q图】用来辅助判断样本数据是否服从正态分布
【做法】做数据的四分位数(四分之一划分):25%、50%、75%,即是Q-Q图
【解释】数据上怎么分布的?Q是的首字母,表示四分位数图
【拓展】假如数据不是正态分布的
平均数:那么平均数去失去了作用中位数:这时候,中位数就能更好的描述数据四分位数:25%、50%(中位数)、75%

2 空间自相关分析
【空间自相关】空间中相近的样点具有某种相似性,相距较远的样点往往不相似
【作用】解释和寻找存在的空间聚集性或“焦点”
【举例】把小偷的点标在地图上,用空间自相关来分析,找哪里是贼窝
【举例】叶子的分布:没有风吹,距离越近,叶子是越厚的。风一吹,越远叶子越薄
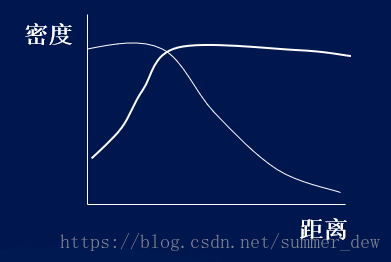
【变异】越近空间越相似–>反过来说:越近空间变异越少,越远空间的变异越大
2.1 类型 全局(全程)自相关局部自相关:相关的范围

2.2 自相关的解释 正自相关:属性值的差异随距离变小越相似负自相关:反向相关,属性值的差异随距离变小越不相似0:属性值的差异与距离没有关系 2.3 自相关性测度
自相关的定量判定,三个统计量
’参数 2.3.1 权重矩阵
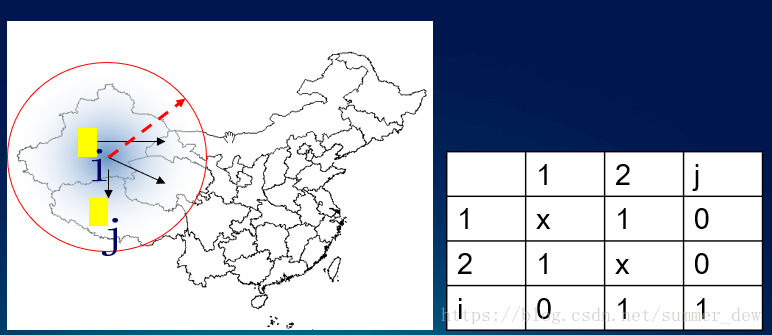
【解决的问题】数据的关系,怎么引入到计算里呢?空间权重矩阵(w矩阵)
【空间权重矩阵】是空间自相关分析的基础
空间数据中隐含的拓扑信息提供了空间邻近的基本度量,这通常可通过二元对称的空间权重矩阵W来表达
【怎么做的?】约定:相邻定义为1,不相邻定义为0 --> 产生了一个0、1表
【注意】所有相关的度量都需要经过检验,不以值的高低断英雄,而在置信区间和显著性(要做一个概率检验、显著性检验)
【自相关的取值范围】[-1,1]
【例子】I=0.001,这个关系是强还是弱呢?不知道,必须做检验。根据检验之后才知道
【原因】I的大小和样本数是有关系的
数据量少,只有两个点的时候,I=0.1那相关性肯定是很弱的数据量有一个亿,I=0.1那相关性就已经是很强的了 2.3.2 ’sI
【’sI】包括全程和局部两个参数,用来分析空间的相关性

【解释】w=1即是任意一个数对于均值的偏差,和方差的公式很像,只是加了一个w(距离比较近才计算,比较远w=0就不计算了)
【意义】I值越大,表明正的空间相关性越强
正相关:如果是正的而且显著,表明具有正的空间相关性。 即在一定范围内各位置的值是相关的负相关:如果是负值而且显著的,则具有负的空间相关性,数据之间反相关随机:接近于0则表明数据的空间分布是随机的,没有空间相关性 2.3.3 参数
【应用场景】进行局部自相关分析
【意义】C值大于0,表明正的值四周为高值环绕,小于0,则为低值环绕,0则为无聚集特征。
2.3.4 G统计量
【应用场景】局部自相关分析
【意义】较高的G值表明位置周围是较高的数据,即数据具有聚集性
【结论】模拟表明 (Ord 和 1994),在xi 周围不存在空间聚集的原假设的条件下,G的分布接近与正态。对于不同的观察值N,在不同的显著性概率下G值各不相同。
【例如】在90%的概率下,N=40对应的G值为2.7913
2.4 应用问题
什么情况下要用空间自相关,用空间自相关用来研究什么问题
【问题】常识是否需要证明?
你已经知道你的研究对象就是聚集的,你还用空间自相关去做,这就没有必要了
【例子】
蚂蚁在空间上是不是空间自相关的?所以不能用空间自相关来研究蚂蚁,蚂蚁就是一窝一窝的研究蝗虫在空间上是不是空间自相关?可以的,原先没有这个概念